Faz o database ser mais robusto contra falhas ao pegar novos Clients de conexão
#197
Conversation
|
This pull request is being automatically deployed with Vercel (learn more). 🔍 Inspect: https://vercel.com/tabnews/tabnews/CTenqbtidhwgG1wCpkR6xfDqJSUR |
1ac6840 to
49d9c34
Compare
49d9c34 to
f4660cf
Compare
f4660cf to
4590fa3
Compare
4590fa3 to
21b29de
Compare
|
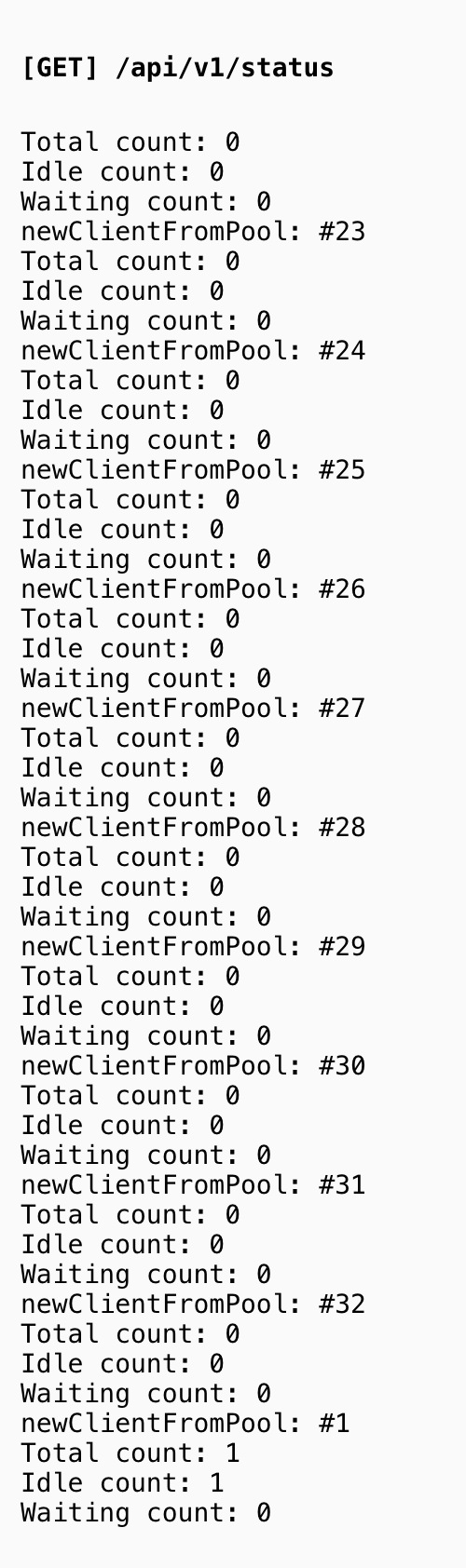
Estou fazendo testes contra o ambiente de Preview (100 conexões em paralelo) e tanto o Pool quanto o Retry estão se comportando como esperado, porém algo não esperado obviamente aconteceu: por algum motivo, algumas queries ficam presas lá no serviço do banco de dados, olha só:
E quando isso acontece, fica ocupando as conexões e não tem tentativa que aguente, pois a Lambda é terminada depois de 60 segundos:
Se alguém tiver alguma sugestão do que fazer seria show 😍 |


21b29de to
feaaf40
Compare
|
Olha que massinha, eu consigo reproduzir o travamento das queries com
To tentando agora entender porque as queries travam quando o server fica atolado 👍 |
feaaf40 to
da49026
Compare
da49026 to
c5bfc09
Compare
c5bfc09 to
3c9b68b
Compare
3c9b68b to
a276ac9
Compare
a276ac9 to
1c47c12
Compare
1c47c12 to
745c199
Compare
745c199 to
ac65113
Compare
ac65113 to
98d1545
Compare
98d1545 to
0fae942
Compare
|
Saí agora pouco de um call com 3 pessoas fantásticas do Pagar.me: @gustavolivrare @lucianopf @grvcoelho Esse call aconteceu da forma mais maluca e espontânea possível 😂 e a gente conseguiu melhorar esse PR para lidar com muito mais conexões do que estava antes e o segredo foi, por incrível que pareça, parar de usar o Pool e gerenciar manualmente o Client de conexão. Num cenário serverless e distribuído como o da Vercel, junto com um banco que dá no máximo 5 conexões simultâneas, a pior escolha é usar o Pool, porque ele vai segurar as conexões para poder reaproveitar elas, (bloqueando conexões que poderia ser abertas por outras instâncias), e com o agravante de que a lamba em que tudo isto está sendo gerenciado é encerrada dentro de 60 segundos, aparentemente impedindo com que o Pool feche os clients abertos, deixando eles pendurados lá, como a gente viu no print abaixo. Então se o encerramento da lambda impede o Pool de fazer seu trabalho até ao final (que é desconectar os clients), você vai lotar suas conexões.
Então nesse cenário (e que não serve para quando você trabalha com instâncias menos efêmeras), acabou sendo muito melhor tentar abrir uma conexão, fazer o que for preciso, e fechar ela o mais rápido possível. Isso penaliza a performance, pois a todo momento precisamos abrir uma nova conexão, mas para esse cenário de conexões limitadas, ficou excelente. E como esse é o "worst-case scenario", daqui pra frente só melhora 👍 |

Não sei até que ponto isso vai funcionar na vida real, mas subiu a estabilidade da aplicação para outro nível (mas só a vida real vai dizer se isso se sustenta 😂 ) e foi uma das coisas mais delicinha que eu programei até então.
Contexto: quem viu o último vídeo do TabNews, acompanhou que uma hora no meio do tutorial o banco engasgou, do nada, e isso "aparentemente" só estava acontecendo localmente e sem padrão algum (porque nunca aconteceu no CI). Pensei que era minha máquina e fiquei analisando o banco, número de conexões abertas e não encontrava nada... a aplicação do Next.js simplesmente engasgava, só que em paralelo eu conseguia conectar normalmente no banco usando um Client externo. No final das contas, era eu quem estava fechando por completo o Pool de conexões a todo momento, achando que eu estava apenas fechando a conexão de um Client específico e que foi aberta manualmente.
Então como funciona o
pgnesse sentido (e pensando aqui toda estratégia de Pool com Postgres): sempre você está com um Client em mãos para trabalhar... mas que pode ser adquirido de duas formas: manualmente abrindo a conexão e com isso tendo em mãos um Client, ou pedindo para o Pool por um Client disponível que esteja lá na fila parado e aguardando ser utilizado. Eu pensei que você se conectava contra um Pool, mas não, ele só administra Clients que ele mesmo está abrindo e fechando.E quando você precisa de um Client manual? Quando você faz uma transaction (que no Postgres deve sempre manter na mesma conexão) ou bibliotecas que pedem um Client conectado, como a
node-pg-migrateque usamos, que por dentro usa uma transaction e passa pra você a responsabilidade de encerrar ela ao final.Então antes eu pedia um Client e encerrava o Pool (porque ele estava vindo de lá). Agora não, você pode usar o
getNewClient()para pegar um client e odatabase.query()vai continuar usando de forma transparente o Pool.Mas o que trouxe "robustez" foi outra coisa
Parar de fechar o Pool foi um bug que eu introduzi por me confundir com a api do
pg, mas deixar odatabasemais robusto quando você tem poucas conexões disponíveis foi feito através de uma estratégia de retry.Tanto para pegar um Client manualmente ou do Pool, o código fica repetidamente pedindo por um novo Client, tentando, tentando, tentando (com máximo de 50 tentativas) e quando conseguir pegar um com sucesso, o código continua. E por continuar pode ser simplesmente retornar o Client, ou rodar uma query. Importante destacar que "rodar a query" fica fora das tentativas... a única coisa que se tenta é pegar um Client saudável.
E isso pode ser usado no método de quey:
Testes de carga em localhost
Usei o
abpra tentar arrebentar aqui o serviço local tanto com5conexões disponíveis no Postgres, quanto1única conexão e a aplicação se comportou muito melhor do que eu esperava. A única forma que consegui estourar foi chegando no limite dos sockets do sistema operacional.Fiquei muito feliz porque isso nos habilita a usar serviços mais baratos de Postgres (e que vem com uma quantidade pequena de conexões), com o agravante de estarmos num ambiente serverless e que pode abrir infinitas conexões. Mas novamente, só a vida real vai nos dizer o que vai acontecer.
Em paralelo, confere essa issue #196 onde o @andrefd17 deu duas dicas sensacionais de ferramentas pra teste de carga.
Número máximo de conexões
Agora o endpoint
/api/v1/statusretorna o número máximo de conexões do banco no campomax_connections. Vai ficar mais rápido e fácil saber o que de fato nosso provider de banco de dados está nos entregando:{ "updated_at": "2022-02-23T10:20:17-08:00", "dependencies": { "database": { "status": "healthy", "max_connections": 4, "opened_connections": 1 } } }[edit]
Não pera, testando em staging está retornando
"max_connections": 10000😂 vou tentar isolar para o nosso banco, como fizemos emopened_connections.[edit2]
Não tem jeito, não consigo isolar por user ou database, mas coloquei um TODO ali caso alguém saiba como pegar esse número em um banco de dados compartilhado.
[edit3]
Consegui: